


Критичка анализа на индустриска визуелна конвенција и предлог за академски одбранлива поделба
Институт за родови студии, Филозофски факултет, Универзитет „Св. Кирил и Методиј“, Скопје
Апстракт
Во индустрискиот дискурс за вештачка интелигенција сè почесто се сретнува троделна поделба на LLM-засновани системи на „generative AI“, „agentic AI“ и „AI agents“. Поделбата циркулира преку корпоративни блогови, инфографики на социјални мрежи и наставни материјали, но најчесто без академски извори и со внатрешни концептуални противречности. Овој текст ја анализира една таква широко споделувана инфографика како репрезентативен случај, ги изложува нејзините технички и логички недостатоци, и нуди прецизирана поделба заснована на единствена оска: кој носи одлуки за контролниот тек на системот — корисникот, кодот или моделот. Прецизираната поделба ја задржува троделната структура која е педагошки корисна, ѝ дава операционализирани дефиниции, и експлицитно ја мапира кон конкурентните терминолошки конвенции кај Anthropic, Google Cloud и MIT Sloan. Заклучокот укажува дека ваквите инфографики функционираат како „гранични објекти“ во дискурсот за вештачка интелигенција: педагошки корисни како почетна точка, но епистемолошки ризични кога се користат како единствен извор за концептуализација.
Клучни зборови: вештачка интелигенција, големи јазични модели, агентни системи, автономија, индустриска терминологија, инфографика, педагогија.
1. Вовед
Во последните две години, со растечката достапност на големи јазични модели (LLM) и нивно вградување во разни облици на производи, во индустрискиот и медиумскиот дискурс за вештачка интелигенција се востанови една специфична визуелна конвенција: тро-делена компаративна табела или тро-колонски процесен дијаграм во кој се прикажуваат „generative AI“, „agentic AI“ и „AI agents“ како три различни типа на системи. Овие инфографики циркулираат на LinkedIn, корпоративни блогови, обуки за менаџери, а сè почесто навлегуваат и во наставни материјали на универзитетски курсеви.
Иако визуелизациите од овој тип имаат педагошка функција — им помагаат на читателите да градат прва ментална мапа на едно ново и брзо менувачко поле — тие истовремено создаваат специфичен епистемолошки ризик. Тие репродуцираат како „факт“ една категоризација која во самата академска и техничка литература сè уште не е стабилизирана, и често ја прават тоа без наведување извор, автор или датум. Резултатот е дискурзивна формација во која конвенцијата претходи на дефиницијата.
Овој текст ја анализира една таква инфографика — широко споделувана на социјалните мрежи во 2024 и 2025 година — како репрезентативен случај. Прв чекор е дескриптивен: што точно прикажува инфографикот и кои се неговите структурни недостатоци. Втор чекор е дискурзивен: како вакви визуелизации функционираат во индустрискиот семантички систем дури и кога се концептуално нестабилни. Трет чекор е конструктивен: нуди прецизирана поделба со операционализирани дефиниции и експлицитно мапирање со конкурентните терминолошки конвенции во литературата.
Тезата на текстот не е дека тро-делената поделба треба да се отфрли, туку дека треба да се реконструира врз единствена концептуална оска и со експлицитна свест за нејзината терминолошка локалност. Поделбата „чет / чет + алатки / самостоен извршител“ е педагошки корисна и одбранлива, под услов да биде поставена врз оската на автономија и контрола, а не како онтолошки различни „типови“ на вештачка интелигенција.
2. Анализа на инфографиката како случај
Инфографиката што се анализира тука прикажува три паралелни вертикални колони со наслови „Generative AI“, „Agentic AI“ и „AI Agents“. Секоја колона содржи процесен дијаграм со осум до девет чекори означени со икони и стрелки, а под трите колони се наоѓа компаративна табела со пет реда: цел, функционалност, примери, интеракција со системот и способност за учење. Инфографиката нема наведен автор, нема датум и нема библиографски извори.
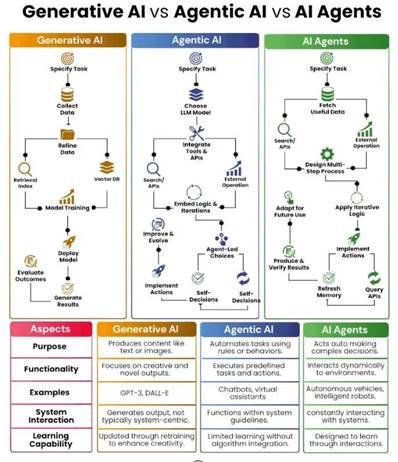
Иако визуелно делува информативно и сеопфатно, на поблиско читање покажува неколку структурни проблеми кои го компромитираат нејзиното функционирање како научен материјал.
2.1. Замаглување на фазите на тренирање и инференција
Процесниот дијаграм за „Generative AI“ ги мапира следните чекори: специфицирање на задача, собирање податоци, рафинирање на податоците, поставување на индекс за пребарување и векторска база, тренирање на модел, распоредување (deployment), евалуација и генерирање резултати. Овој ред меша две сосема различни нешта: фаза на создавање на моделот (од собирање податоци до тренирање и распоредување) и фаза на користење на моделот (специфицирање задача, генерирање резултати).
Креирањето на модел е процес што го извршуваат компании како OpenAI, Anthropic или Google со огромни ресурси и временски рокови; користењето на готов модел е процес што го извршува секој краен корисник за неколку секунди по испратеното барање. Прикажувањето на овие два процеса како чекори во ист тек создава впечаток дека секој корисник на ChatGPT минува низ фаза на „тренирање на модел“ како дел од својата интеракција, што е суштинска грешка во разбирањето на тоа како функционираат LLM-засновани системи.
2.2. Структурна идентичност на колоните „Agentic AI“ и „AI Agents“
Процесните дијаграми за „Agentic AI“ и „AI Agents“ при внимателно споредување се покажуваат како структурно идентични. Колоната за „Agentic AI“ опфаќа: избор на LLM, интеграција на алатки и API, вградување на логика и итерации, подобрување и еволуирање, „агентно-водени“ одлуки, имплементирање на акции и самостојни одлуки. Колоната за „AI Agents“ опфаќа: преземање корисни податоци, надворешни операции, дизајнирање на повеќестепен процес, прилагодување за идна употреба, применување на итеративна логика, имплементирање на акции, освежување на меморија и повикување на API.
Чекорите „вградување логика и итерации“ и „дизајнирање повеќестепен процес“ опишуваат истата активност со различни именки. Истото важи за „агентно-водени одлуки“ и „применување на итеративна логика“, како и за двата „имплементирање на акции“. Разликата меѓу овие две колони е реторичка, не процедурна, и токму затоа функционира како визуелна реторика на „напредност“ без вистинска концептуална основа.
2.3. Внатрешно противречно тврдење за способноста за учење
Долната табела во редот „способност за учење“ содржи следните тврдења: „Updated through retraining to enhance creativity“ за Generative AI, „Limited learning without algorithm integration“ за Agentic AI, и „Designed to learn through interactions“ за AI Agents.
Тврдењето за Agentic AI е концептуално нејасно — фразата „ограничено учење без интеграција на алгоритми“ не значи ништо одредено во техничка смисла, бидејќи секој LLM-заснован систем по дефиниција содржи алгоритамска компонента. Дополнително, ако „AI Agents“ во оваа поделба се поедноставен пример (како што колоната за Agentic AI визуелно сугерира со помал број чекори), не може истовремено да биде претставен како подобар во учењето. Редот „способност за учење“ се самокомпрометира — категоризацијата што визуелно расте по сложеност текстуално опаѓа по способност за учење на средната точка.
2.4. Мешани онтолошки нивоа во редот „примери“
Редот „примери“ во долната табела ги наведува следните единици: GPT-3 и DALL-E за Generative AI, чет-ботови и виртуелни асистенти за Agentic AI, и автономни возила и интелигентни роботи за AI Agents. Тие три ставки припаѓаат на три сосема различни онтолошки нивоа: конкретни производи (GPT-3, DALL-E), категории на софтвер (чет-ботови, виртуелни асистенти), и физички автономни системи (возила, роботи). Дополнително, „автономни возила“ и „интелигентни роботи“ не се LLM-засновани агенти во строга смисла; тие припаѓаат на полето на робототика и computer vision со свои децениски истражувачки традиции, кои се појавиле многу пред современите LLM-системи и користат различни архитектури.
2.5. Отсуство на извор, автор и датум
Инфографиката нема наведен автор, институција, датум на изработка ниту библиографски извори. Овие елементи се стандард во академскиот дискурс не како формалност, туку како епистемолошка гаранција: тие му овозможуваат на читателот да провери, контекстуализира и спореди тврдењата со други извори. Нивното отсуство ја префрла инфографиката во жанрот на анонимна индустриска визуелизација, чија авторитативност произлегува од визуелниот стил и брзината на циркулирање, а не од проверливоста на содржината.
3. Дискурзивен статус на поделбата
И покрај наведените недостатоци, тро-делената поделба „generative / agentic / agents“ е широко прифатена низ корпоративниот, образовниот и дел од стручниот дискурс. Овој социјален факт треба сериозно да се земе предвид: ако одредена категоризација е оперативна во еден значителен дел од дискурзивниот простор, академскиот текст не може едноставно да ја прогласи за погрешна и да продолжи. Треба прво да се разбере зошто таа функционира, и потоа да се идентификува што може да се поправи во неа без да се изгуби нејзината педагошка вредност.
Терминолошкото поле во кое се движат овие категории е во состојба на полу-стабилизирана употреба. Различни големи играчи во полето користат значително различни дефиниции. Anthropic, во влијателниот текст на Schluntz и Zhang (2024), сите системи што користат LLM за извршување задачи ги нарекуваат „agentic systems“ како чадор-поим, и потоа прават архитектонска разлика помеѓу „workflows“ — системи каде LLM и алатки се оркестрирани преку предефинирани кодни патеки — и „agents“ — системи каде LLM динамички ги насочуваат сопствените процеси и употребата на алатки. Во оваа терминологија, „agent“ е токму највисокото ниво на автономија, а „agentic“ е чадорот за сите варијанти. Google Cloud, во својата официјална дефиниција, ја позиционира „agentic AI“ како подмножество на „generative AI“, а „AI agents“ како „градежни блокови“ на agentic AI, што е спротивно од поделбата во инфографиката. MIT Sloan, преку текстовите на Sinan Aral, „agentic AI“ ја дефинира како системи кои инкорпорираат повеќе различни агенти кои заедно оркестрираат задача, што е поблиску до класичниот концепт на мулти-агентни системи кај Wooldridge (2009).
Овие конкурентни употреби не се грешки во меѓусебно поправање, туку различни тематизации на истиот концептуален простор. Како што Russell и Norvig (2020) укажуваат во стандардниот учебник по вештачка интелигенција, поимот „агент“ во полето на AI има децениска историја и веќе значи нешто прецизно: ентитет што перцепира средина преку сензори и дејствува на средината преку акутатори, со цел да максимизира одредена мерка за изведба. Сите Russell-Norvig дефиниции на типови агенти — рефлексни, моделно-засновани, цел-засновани, корисносно-засновани и учечки агенти — се типови на еден и ист онтолошки ентитет. Терминот „agentic“ како посебна категорија спротивна на „agent“ не постои во оваа традиција.
Што значи тогаш дека поделбата „generative / agentic / agents“ во индустрискиот дискурс сепак функционира? Една продуктивна интерпретација е дека таа функционира не како таксономска тврдња, туку како прагматична скала на интеграција и автономија. Помеѓу „чист LLM во разговор“ и „автономен агент што извршува повеќестепена задача“ постои реален континуум на архитектонски решенија, и трите термини служат како груби маркери на различни точки на тој континуум. Концептуалните проблеми се појавуваат само кога овие груби маркери се претставуваат како онтолошки различни „типови“ на вештачка интелигенција, наместо како нивоа на автономија на еден и ист тип на систем.
4. Прецизирана поделба
Поделбата предложена тука ја задржува троделната структура која е педагошки корисна и широко препознатлива, но ја поставува врз една експлицитна оска: кој носи одлуки за контролниот тек на системот. Контролниот тек овде значи редоследот, изборот и завршувањето на чекорите потребни за извршување на задача. Можните носители на одлуките се три: корисникот (преку директни инструкции во разговор), кодот (преку предефинирани патеки во апликациската логика), и моделот (преку динамичко планирање во моментот).
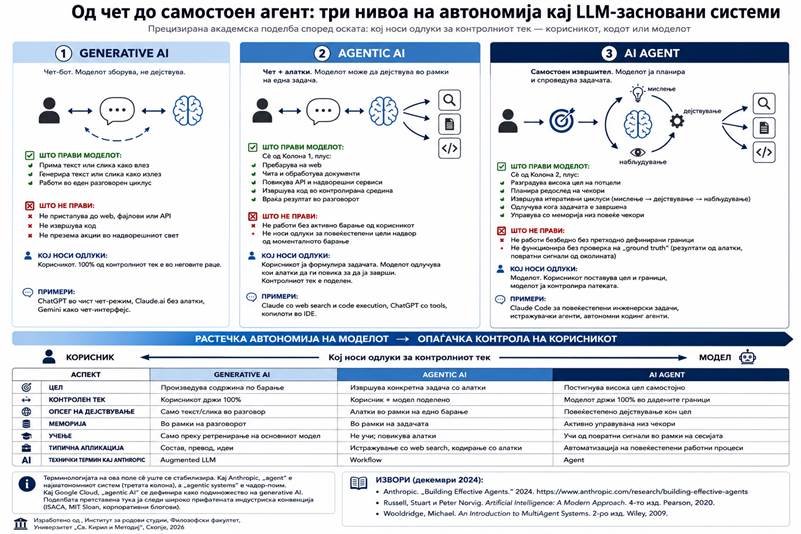
4.1. Generative AI — чет-бот
Прво ниво на поделбата е генеративен модел во чисто разговорен режим. Корисникот пишува, моделот одговара. Циклусот е затворен: моделот произведува текст или слика како излез, без пристап до надворешни системи, без извршување на акции во светот, без управување со меморија надвор од текот на разговорот. Сите одлуки за контролниот тек ги донесува корисникот; ако треба нешто да се направи врз основа на одговорот на моделот, тоа го прави корисникот рачно.
Примери на оваа категорија се ChatGPT во чист чет-режим без вклучени алатки, Claude.ai без пристап до web search или code execution, и Gemini користен исклучиво како разговорен интерфејс. Во терминологијата на Anthropic ова е „augmented LLM“ во неговата најосновна форма — модел со капацитет за генерација, но без надворешни augmentations.
4.2. Agentic AI — чет плус алатки
Второ ниво на поделбата е истиот генеративен модел, но опремен со пристап до алатки: web search, читање и обработка на документи, повикување на API, извршување на код во контролирана средина. Овој пристап му овозможува на моделот да дејствува надвор од границите на чистата генерација — да доведе нови информации, да повика надворешни сервиси, да изврши нумерички пресметки. Сепак, опсегот на дејствување е затворен во рамките на едно корисничко барање: корисникот формулира задача, моделот ја извршува со помош на алатки, и резултатот се враќа во разговорот.
Во оваа категорија, контролниот тек е поделен меѓу корисникот и моделот. Корисникот ја одредува задачата и нејзините граници; моделот одлучува кои алатки да ги повика и во кој редослед за да ја заврши. Сепак, моделот не носи одлуки за повеќестепени цели надвор од моменталното барање, и не задржува иницијатива откако задачата ќе биде завршена. Примери се Claude со web search и code execution, ChatGPT со tools, и копилоти за код вградени во развојни средини. Во терминологијата на Anthropic, ова најчесто соодветствува на „workflows“ — системи каде кодната патека е претходно дефинирана, а LLM-от ја пополнува содржината на чекорите.
4.3. AI Agent — самостоен извршител
Трето ниво на поделбата е генеративен модел кој динамички ги насочува сопствените процеси кон висока цел. Корисникот му задава задача која може да опфаќа повеќе чекори, поставува граници и критериуми за прифатлив исход, а моделот самостојно ја разградува задачата на потцели, планира редослед на чекори, повикува алатки во итеративен циклус, и одлучува кога задачата е завршена. Во овој модел на работа, моделот мора при секој чекор да добива „ground truth“ од средината — резултати од повиканите алатки, повратни сигнали, тестови — за да процени дали се движи кон целта или треба да корегира.
Контролниот тек овде е најголемиот дел во рацете на моделот, со човечкиот надзор поставен на ниво на цели и граници, не на ниво на поединечни чекори. Примери се Claude Code за повеќестепени инженерски задачи, истражувачки агенти кои собираат и анализираат информации од повеќе извори, и автономни кодинг агенти кои извршуваат серии од измени во кодна база. Во терминологијата на Anthropic, ова се „agents“ во прецизна смисла; тоа е она што кај нив е најавтономниот тип на agentic system.
4.4. Терминолошко мапирање
Бидејќи терминологијата во полето е сè уште нестабилна, секоја употреба бара експлицитно мапирање со конкурентните конвенции. Долната табела ги сумира четирите главни употреби на трите термини и нивниот меѓусебен сооднос.
| Извор | Чет-бот (ниво 1) | Чет + алатки (ниво 2) | Самостоен извршител (ниво 3) |
| Anthropic (Schluntz и Zhang 2024) | Augmented LLM | Workflow | Agent |
| Google Cloud | Generative AI | AI agent (component) | Agentic AI (multi-agent orchestration) |
| MIT Sloan / Aral | Generative AI | AI agent (single) | Agentic AI (multi-agent) |
| Индустриска конвенција (анализираната инфографика) | Generative AI | Agentic AI | AI Agents |
Од табелата се гледа дека ниту еден термин не значи исто во сите четири извори. Особено индикативно е дека терминот „agent“ кај Anthropic значи токму она што кај индустриската конвенција го означува терминот „agentic AI“, а терминот „agentic AI“ кај Google Cloud е чадор-поим за најавтономното ниво, а не средно ниво. Овој терминолошки хаос не е грешка во полето; тоа е природна состојба на технолошки дискурс во кој конвенцијата претходи на дефиницијата. Кога академски текст или наставен материјал се однесува на овие категории, мора експлицитно да дефинира која употреба ја следи, бидејќи нема универзално прифатена.
Прецизираната поделба предложена тука ја следи индустриската конвенција за имињата на категориите (Generative AI / Agentic AI / AI Agent), затоа што токму со неа студентите и обичните корисници најчесто се среќаваат во медиумите и корпоративниот дискурс. Од Anthropic ја позајмува содржинската супстанца на дефинициите, особено критериумот „кој носи одлуки за контролниот тек“. Оваа хибридна стратегија ги задржува препознатливите имиња, но им дава техничка прецизност што индустриската конвенција сама по себе ја нема.
5. Заклучок: педагошка вредност и епистемолошки ризик
Инфографиките како онаа анализирана во овој текст функционираат во дискурзивниот простор како „гранични објекти“ — единици што служат на различни групи (продажба, обука, едукација, инженерство) дури и без концептуална прецизност, и токму поради таа полиморфност лесно се распространуваат. Тие нудат брза ментална мапа на едно сложено поле и им помагаат на читателите да преминат од состојба на потполна непредизвикана непознаница кон состојба на работна оперативност. Тоа е реална педагошка вредност и не треба да се отфрла.
Истовремено, постои реален епистемолошки ризик. Кога ваквите инфографики се користат како единствен извор, тие репродуцираат концептуални противречности како да се факти, мешаат онтолошки нивоа, и ја заматуваат разликата помеѓу прецизни технички термини и нивните маркетиншки употреби. Кога влегуваат во наставни материјали без критичка реконструкција, ги поучуваат студентите на површно разбирање што подоцна треба да се откорнува.
Препораката што произлегува од оваа анализа за наставниците кои работат со ваквите материјали е тројна. Прво, инфографиките можат да се користат како почетна точка во настава, особено за студенти кои се новајлии во полето, бидејќи нудат препознатлив и достапен влез. Второ, веднаш по таквото воведување, наставникот треба да го направи експлицитен критичкиот чекор: да укаже што во инфографиката е концептуално нестабилно, да понуди прецизирана дефиниција, и да го мапира преземениот вокабулар со конкурентните терминолошки конвенции. Трето, при подготовка на сопствени материјали, наставникот треба да следи академски стандарди што инфографиките не ги почитуваат: наведување извор, автор, датум, и експлицитна свест за тоа од каде доаѓаат концептите што се користат.
Поделбата „чет / чет + алатки / самостоен извршител“, поставена врз оската на автономија и контрола, е педагошки одбранлива и операционализирана. Таа не претставува онтолошка таксономија на различни типови вештачка интелигенција, туку прагматична скала на интеграција и автономија помеѓу LLM-засновани системи. Како таква, може да биде солидна основа за вовед во полето, но не и крајна теориска точка. Студентот кој ќе ја разбере оваа поделба треба следно да навлезе во прецизните технички дистинкции (workflow vs. agent, augmented LLM, tool use, ground truth), и таму индустриската конвенција престанува да биде корисна и почнува да биде препрека.
Библиографија
Aral, Sinan. 2026. „Agentic AI, Explained.“ Интервју со Beth Stackpole. MIT Sloan Ideas Made to Matter, 23 февруари. https://mitsloan.mit.edu/ideas-made-to-matter/agentic-ai-explained.
Google Cloud. без датум. „What Is Agentic AI? Definition and Differentiators.“ Пристапено на 15 мај 2026. https://cloud.google.com/discover/what-is-agentic-ai.
Ransbotham, Sam, David Kiron, Shervin Khodabandeh, Sukhada Iyer и Anya Das. 2025. „The Emerging Agentic Enterprise: How Leaders Must Navigate a New Age of AI.“ MIT Sloan Management Review and Boston Consulting Group, ноември. https://sloanreview.mit.edu/projects/the-emerging-agentic-enterprise-how-leaders-must-navigate-a-new-age-of-ai/.
Russell, Stuart и Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4-то изд. Hoboken: Pearson.
Schluntz, Erik и Barry Zhang. 2024. „Building Effective Agents.“ Anthropic, 19 декември. https://www.anthropic.com/research/building-effective-agents.
Wooldridge, Michael. 2009. An Introduction to MultiAgent Systems. 2-ро изд. Chichester: John Wiley & Sons.