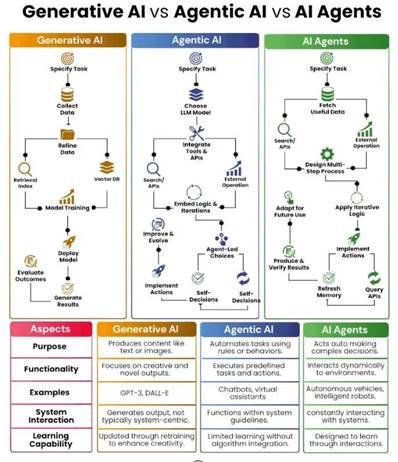
Родовата пристрасност во системите на вештачка интелигенција (ВИ) е длабоко вкоренета во историските и структурните нееднаквости на општеството. Оваа пристрасност често влегува во системите преку податоците за тренирање, кои ги одразуваат веќе постоечките културни и социјални стереотипи на човештвото. Технолошкиот сектор историски е доминиран од мажи, што довело до вградување на машката перспектива и вредности во самиот дизајн на алгоритмите. Почетоците на ВИ истражувањата се врзани за т.н. WEIRD популации (Западни, Образовани, Индустријализирани, Богати и Демократски), чии податоци доминираат во моделите и често не се претставителни за остатокот од светот или за маргинализираните групи.
Пристрасноста во податоците за тренирање
Пристрасноста во податоците за тренирање на системите на вештачка интелигенција (ВИ) е емергентен феномен на ситуираното знаење и општествените структури на моќ. Според феминистичката епистемологија, технологијата никогаш не е неутрална, таа ги рефлектира вредностите на своите креатори и историскиот контекст во кој е создадена. Историските и структурните причини за оваа пристрасност се вплетени во самиот процес на прибирање, обработка и означување на податоците.
Историската пристрасност произлегува од податоци кои во себе носат веќе постоечки културни и социјални стереотипи, генерирани во време кога дискриминаторските обрасци биле нормализирани. Ова често се манифестира преку родово обоени јазични модели, каде што професиите се поврзуваат со специфичен пол, на пример, „медицинска сестра“ како женски род наспроти „доктор“ како машки род, со што алгоритмите само ги засилуваат патријархалните кодови на општеството.
Структурните причини за пристрасност се огледуваат во доминацијата на т.н. WEIRD популации (Западни, Образовани, Индустријализирани, Богати и Демократски) во базите на податоци што се користат за тренирање. Овој дисбаланс значи дека ВИ моделите се обучуваат на искуствата на привилегираните групи, додека маргинализираните заедници, како луѓето со различна боја на кожа или лицата од пониските социо-економски класи остануваат невидливи или се третираат како „отстапување“ од нормата. Кога ваквите непретставителни податоци се користат за системи што донесуваат одлуки во образованието, вработувањето или судството, тие резултираат со дискриминаторски исходи кои ги продлабочуваат социјалните поделби.
Дополнително, се јавува ризикот од „mode collapse“ (колапс на модусот), каде што алгоритмите ги фаворизираат најчестите (доминантните) исходи, дополнително потиснувајќи ги специфичните културни наративи кои се веќе недоволно застапени во дигиталните архиви. Појавата на ваквата системска нерамнотежа е рзултат на тренингот на јазичните модели кои најчесто учат од секундарни извори, она што луѓето го напишале за одредена култура, а не од директно набљудување, што дополнително ја искривува реалноста во корист на оние кои имаат поголема моќ на претставување.
Репрезентацијата на жените во технолошката индустрија и нејзиното влијание
Репрезентацијата на жените во технолошката индустрија не претставува само прашање на еднакви можности за вработување, образование, здравство и сл. Технолошкиот сектор историски е карактеризиран со значајна машка доминација, што директно влијае врз начинот на кој се развиваат и имплементираат новите технологии. Доминантната „bro-culture“ во ИТ индустријата дејствува како бариера што ги оддалечува жените од технологијата, со што се одржува родовата нерамнотежа и се ограничува диверзитетот на перспективи во развојните тимови.
Недостатокот на женска репрезентација во дизајнот води кон вградување на патријархални стереотипи во самите производи. Дигиталните асистенти, како Siri и Alexa, често се дизајнирани со женски гласови и субмисивни карактеристики, со што се нормализира и репродуцира културната претстава за жената како услужна фигура. Оваа „родова перформантивност“ на машините влијае врз социјалната перцепција и ги зајакнува традиционалните родови улоги, каде што машките агенти се доживуваат како рационални и авторитативни, додека женските како емоционални и услужни. Ваквиот дизајн не е случаен, тој е резултат на развојни процеси во кои искуствата на белите, добро ситуирани мажи се земаат како стандардна норма, додека потребите на жените остануваат во „слепа точка“.
Влијанието на ниската застапеност на жените се протега и врз алгоритамската дискриминација во реалниот свет. Истражувањата покажуваат дека алгоритмите за препорака на работни места често ги фаворизираат машките кандидати за технички и раководни позиции, со што директно се засилува родовата сегрегација на пазарот на труд. Во контекст на академските истражувања, историскиот фокус на мажите довел до недоволно препознавање на придонесите на жените и недостаток на анализа за нивните специфични потреби. Овој „информативен мрак“ е особено видлив во истражувањата спроведени кај женските невладини организации во Македонија, каде што слабата техничка опременост и недостигот на дигитални вештини дополнително ги исклучуваат жените од влијание врз ИКТ политиките.
Феминистичка критика на дизајнот на ВИ системите
Феминистичката критика на дизајнот на системите на вештачка интелигенција (ВИ) започнува со деконструкција на митот за технолошката неутралност, тврдејќи дека технологијата ги рефлектира вредностите и моќта на оние што ја создаваат. Според феминистичката епистемологија, секое знаење е ситуирано, што значи дека социјалната позиција на дизајнерот директно ја обликува објективноста и авторитетот на системот. Се посочува дека историската машка доминација во ИТ индустријата довела до вградување на маскулини вредности во кодот, притоа занемарувајќи ги емоционалноста, интуицијата и контекстуалноста како релевантни фактори за дизајнот.
Феминистичките теоретичарки аргументираат дека ВИ системите често оперираат врз основа на бинарни и хетеронормативни претпоставки, што води кон маргинализација на квир, транс и небинарните идентитети кои не се вклопуваат во овие фиксни социјални категории. Современата критика го користи концептот на „киборг феминизам“ на Дона Харавеј, кој предлага надминување на строгите граници помеѓу човечкото тело и технологијата, како и помеѓу традиционалните машко-женски опозиции.
Феминистичкиот дизајн инсистира на препознавање на различностите и вклучување на маргинализираните гласови уште во почетните фази на развојот на алгоритмите. Ваквата перспектива ги разоткрива репрезентациските штети кои настануваат кога „стандардниот корисник“ во дизајнот се замислува исклучиво како млад, бел и технички писмен маж. Овој пристап создава системски „слепи точки“ каде што другите групи се третираат како „отстапување“ од нормата или се целосно невидливи за системите за препознавање лица и медицинските класификации. Како одговор, се предлагаат методологии како „Safety by Design“ и survivor-centered пристапи, кои бараат проактивно вградување на етички и безбедносни механизми во самата архитектура на системите за да се спречи технолошки фасилитираното насилство
Интерсекционалноста применета на ВИ
Интерсекционалниот пристап во проучувањето на вештачката интелигенција (ВИ) нуди аналитичка рамка за разбирање на тоа како различните оски на идентитетот, расата, родот, класата, сексуалната ориентација и попреченоста, се преплетуваат и создаваат специфични искуства на дискриминација или привилегија. Оваа перспектива ја деконструира идејата за технологијата како неутрална алатка, откривајќи дека ВИ системите често дејствуваат како носители на кодови кои истовремено ги зајакнуваат и реинтерпретираат доминантните наративи на нееднаквост. Кога алгоритмите се дизајнираат без интерсекционална свесност, тие ризикуваат да ги репродуцираат комплексните структури на предрасуди вкоренети во социо-културниот контекст.
Пристрасноста во податоците и алгоритмите често произлегува од фактот што „стандардниот корисник“ во технолошката индустрија историски се замислува како млад, бел, технички писмен и добро ситуиран маж. Оваа привилегирана позиција води кон т.н. репрезентациски штети, каде што одредени групи, особено жените со различна боја на кожа, се „бришат“ или остануваат невидливи за алгоритмите. Еден од најекспонираните примери е неспособноста на технологиите за препознавање лица прецизно да ги идентификуваат корисниците со потемна боја на кожа, што директно влијае врз безбедноста и граѓанските права на овие заедници. Во „општеството на црната кутија“, ваквите интерсекционални пристрасности стануваат тешко видливи и уште потешки за преиспитување.
Во контекст на образованието и вработувањето, интерсекционалноста ги разоткрива механизмите преку кои ВИ може да ги продлабочи класните нееднаквости. Таков е примерот со предвидливото моделирање на успехот на учениците во Обединетото Кралство, каде алгоритмите покажале диспропорционално негативно влијание врз учениците од пониските социо-економски слоеви и етничките малцинства. Дополнително, истражувањата покажуваат дека дури и со ист ангажман на платформите за учење, студентите од маргинализираните расни групи имаат помали шанси за успех во споредба со нивните бели врсници, што укажува на вградена системска нерамнотежа која ВИ само ја автоматизира.
Интерсекционалниот пристап е клучен и за справување со технолошки фасилитираното родово базирано насилство (ТФРБН). Решенијата за борба против дигиталното насилство, како што се deepfakes или неовластеното споделување интимни слики, мора да бидат „survivor-centered“ и да ги земаат предвид испреплетените фактори на дискриминација. Без ваква анализа, постои опасност технолошките механизми за заштита да останат неефикасни за жените кои припаѓаат на повеќекратни маргинализирани групи.